Federated Learning
Introduction
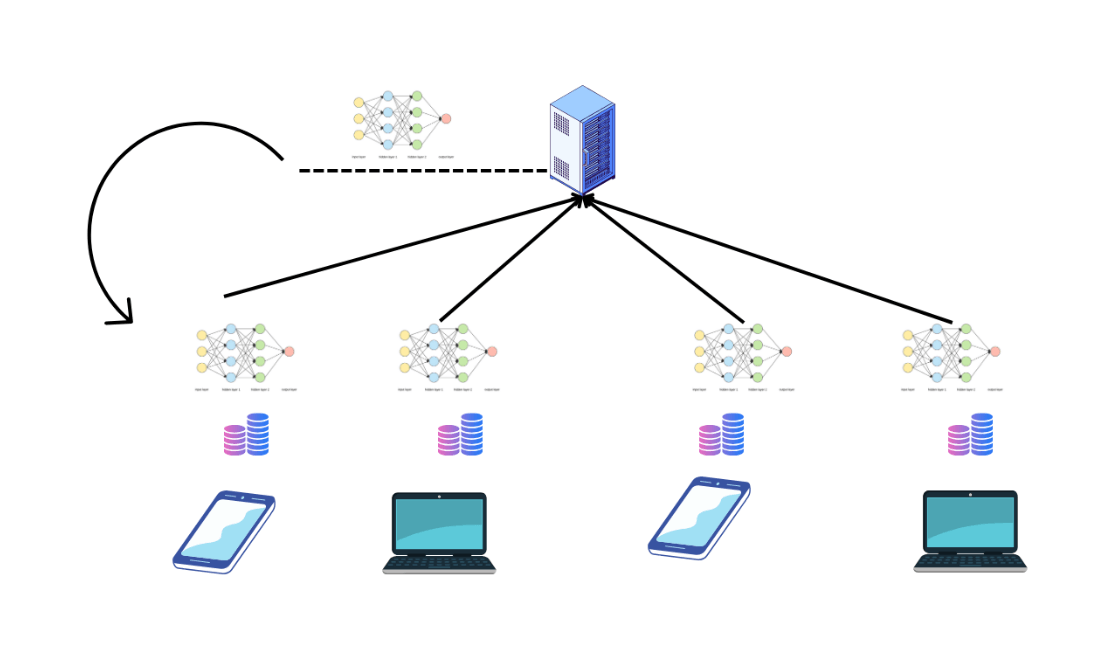
Federated learning is a machine learning technique that allows multiple parties to collaboratively train a machine learning model without sharing their private data. In traditional machine learning, all data is collected and centralized in a single location, such as a server or data center, where the model is trained. However, in federated learning, the data remains decentralized and is stored locally on devices such as smartphones or IoT devices.
In federated learning, the model is initially trained on a small sample of data from each device, and the updated model is then sent back to the devices to improve its accuracy. Each device locally trains the model using its private data and sends the updated model weights to the central server. The server then aggregates the updates and uses them to improve the model. This process is repeated iteratively until the desired level of accuracy is achieved.
Federated learning has the potential to revolutionize the way machine learning models are trained and deployed in various industries. One of its key advantages is that it allows organizations to collaborate and train machine learning models on a large amount of data without the need to centralize or share their data. This preserves data privacy and security, making it particularly useful in scenarios where the data is sensitive, such as healthcare, finance, and personal devices.
The applications of federated learning are wide-ranging and diverse. It can be used in personalized recommendation systems, natural language processing, image and video recognition, and predictive maintenance. However, there are also challenges associated with federated learning. Communication and computational costs can be significant, and there is a risk of biased or inaccurate models.
Despite these challenges, ongoing research and advancements in federated learning are addressing these issues. With further progress, federated learning holds great promise in enabling organizations to leverage large amounts of data for machine learning while preserving privacy and security. This has the potential to transform various industries and unlock new possibilities for machine learning applications.
What is federated learning?
Federated learning (often referred to as collaborative learning) is a decentralized approach to training machine learning models. It doesn’t require an exchange of data from client devices to global servers. Instead, the raw data on edge devices is used to train the model locally, increasing data privacy. The final model is formed in a shared manner by aggregating the local updates.
Here’s why federated learning is important:
Privacy: In contrast to traditional methods where data is sent to a central server for training, federated learning allows for training to occur locally on the edge device, preventing potential data breaches.
Data security: Only the encrypted model updates are shared with the central server, assuring data security. Additionally, secure aggregation techniques such as Secure Aggregation Principle allow the decryption of only aggregated results.
Access to heterogeneous data: Federated learning guarantees access to data spread across multiple devices, locations, and organizations. It makes it possible to train models on sensitive data, such as financial or healthcare data while maintaining security and privacy. And thanks to greater data diversity, models can be made more generalizable.
Architecture of federated learning
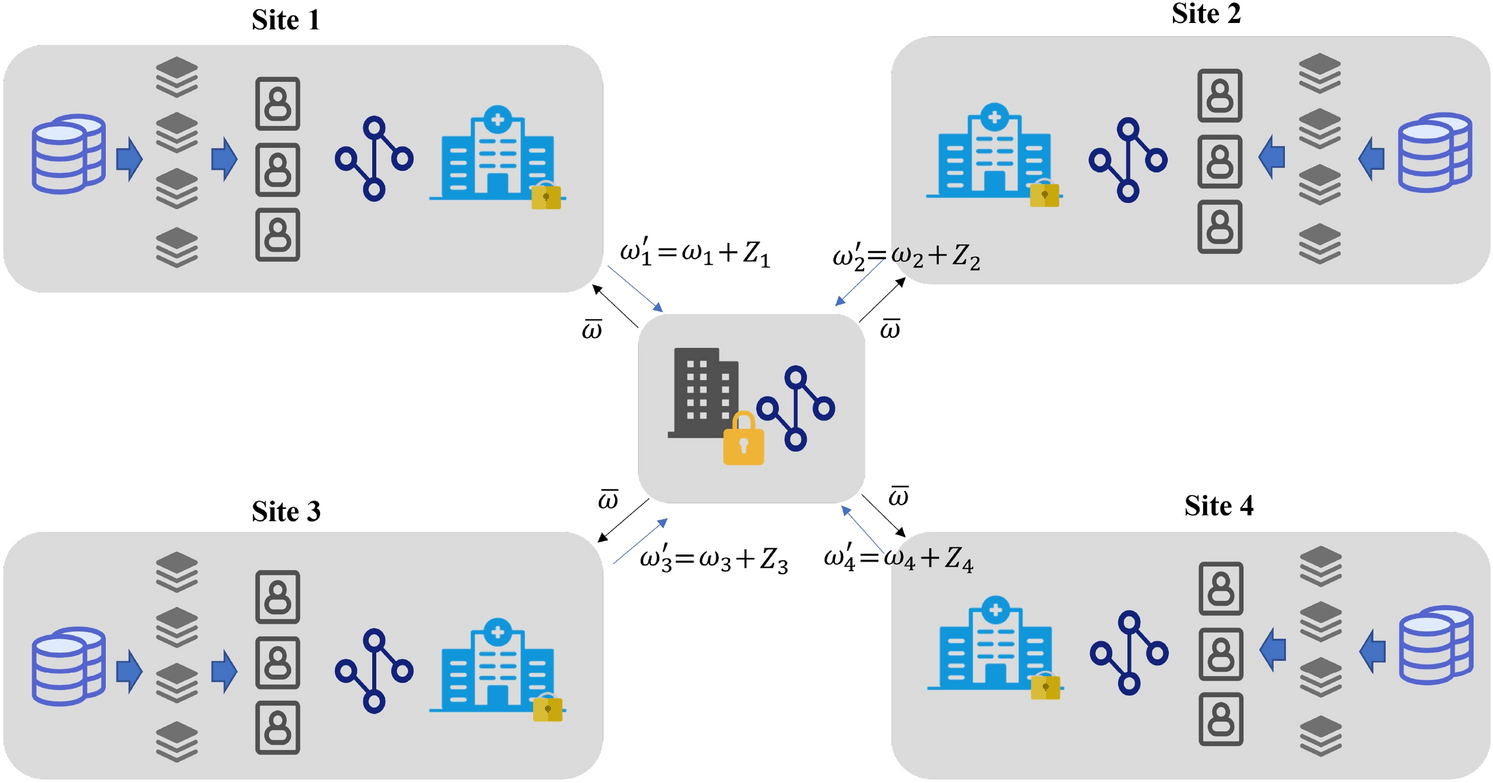
The architecture of federated learning typically consists of three main components: the client devices, the central server, and the machine learning model.
Client devices: The client devices are the endpoints that hold the local data and are used to train the machine learning model. These devices can be mobile phones, laptops, IoT devices, or any other device capable of running a machine learning algorithm. In federated learning, the data remains on the client devices, and the algorithm runs on each device locally.
Central server: The central server acts as a coordinator and aggregator for the training process. It is responsible for managing the training process, aggregating the model updates from the client devices, and sending the updated model back to the devices. The server can also perform additional tasks, such as initializing the model and distributing it to the client devices.
Machine learning model: The machine learning model is the algorithm used to learn from the data on the client devices. The model can be any type of supervised or unsupervised learning algorithm, such as neural networks, decision trees, or logistic regression.
Types of federated learning
According to the distribution features of the data, federated learning may be categorized. Assume that the data matrix represents the information owned by each individual data owner, i.e., each sample and each characteristic are represented by a row and a column, respectively, in the matrix. At the same time, label data may be included in certain datasets as well. For example, we call the sample ID space , the feature space and the label space . When it comes to finance, labels may represent the credit of customers; when it comes to marketing, labels can represent the desire of customers to buy; and when it comes to education, labels can represent students’ degrees. The training dataset includes the features , , and IDs . Federated learning may be classified as horizontally, vertically, or as federated transfer learning (FTL) depending on how the data is dispersed among the many parties in the feature and sample ID space. We cannot guarantee that the sample ID and feature spaces of the data parties are similar.
Federated Transfer Learning (FTL)
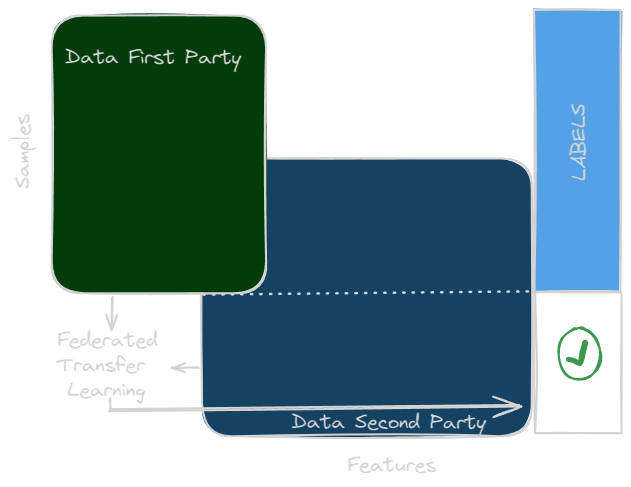
Federated transfer learning is suitable while two datasets differ not only just in sample size but also in feature space. Consider a bank in China and an e-commerce firm in the United States as two separate entities. The small overlap between the user populations of the two institutions is due to geographical constraints. However, only a tiny fraction of the feature space from both companies overlaps as a result of the distinct enterprises. For example, transfer-learning may be used to generate solutions of problems for the full dataset and features under a federation. Specifically, a typical portrayal across the 2 feature spaces is learnt by applying restricted general sample sets as well as then used to produce prediction results for samples with just one-sided features. There are challenges that FTL addresses that cannot be addressed by current federated learning methods, which is why it is an essential addition to the field.
Security Definition for FTL: Two parties are normally involved in a federated transfer learning system. Due to its protocols’ being comparable to vertical federated learning, the security definition for vertical federated learning may be extended here, as will be illustrated in the next.
Vertical Federated Learning
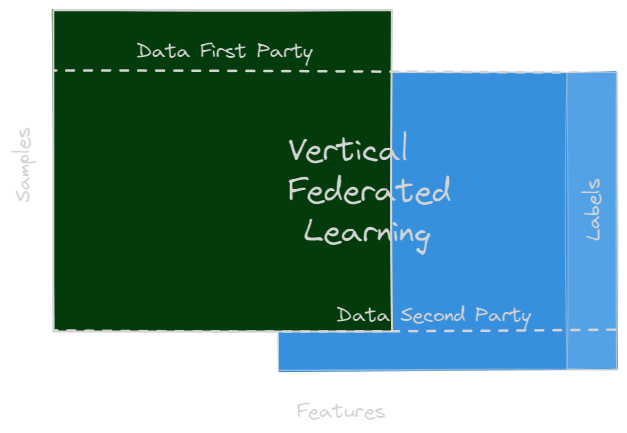 Machine-learning techniques for vertically partitioned data have been suggested that preserve privacy, including gradient descent, classification, secure linear regression, association rule mining, and cooperative statistical analysis. Some studies have presented a VFL method for training a logistic regression model that preserves individual privacy. The authors investigated entity resolution and learning performance, utilizing Taylor approximation to approximate gradient and loss functions for privacy-preserving computations.
Machine-learning techniques for vertically partitioned data have been suggested that preserve privacy, including gradient descent, classification, secure linear regression, association rule mining, and cooperative statistical analysis. Some studies have presented a VFL method for training a logistic regression model that preserves individual privacy. The authors investigated entity resolution and learning performance, utilizing Taylor approximation to approximate gradient and loss functions for privacy-preserving computations.
In the context of VFL, or feature-based FL, two datasets may share the same sample ID space but differ in feature space. For instance, an e-commerce firm and a bank, both operating in the same city, have distinct ways of conducting business. However, their user spaces intersect significantly, as they likely include most of the region’s inhabitants. While banks and e-commerce platforms track customers’ income, spending habits, and credit ratings, their feature sets differ greatly.
Consider a scenario where both parties aim to develop a product purchase prediction model based on product and user data. These distinct characteristics are aggregated, and the training loss and gradients are computed to create a model that incorporates data from both parties jointly.
In a federated learning system, every participating party has the same identity and position, and the federated method facilitates the development of a “common wealth” plan for all involved.
Horizontal Federated Learning

HFL can be applied in scenarios in which datasets at different sites share overlapping feature space but differ in sample space as illustrated in the figure below. It resembles the situation that data is horizontally partitioed inside a tabular view. For example, two regional banks may have very different user groups from their respective regions, and the intersection set of their users is very small. However, their business models are very similar. Hence, the feature spaces of their datasets are the same. Formally, we summarize the conditions for HFL as:
where the data feature spacce and label space pair o fthe two parties, i.e, and are assumed to be the same, whereas the user identifies and are assumed to be different. and denote the datasets of the th party and the th party respectively.
Process of training
Steps training
The federated learning process typically follows the following steps:
Initialization: The machine learning model is initialized on the central server and distributed to the client devices.
Local training: The client devices perform local training on their own data, using the machine learning algorithm.
Model update: After local training, the client devices send their updated model parameters to the central server.
Aggregation: The central server aggregates the model updates from all the client devices, using a specific aggregation strategy, such as averaging or weighted averaging.
Model distribution: The updated model is distributed back to the client devices, and the process starts over again.
Federated learning can also involve multiple rounds of training, where the local training and model update steps are repeated multiple times before the final model is distributed. This process allows the model to learn from a larger dataset and converge to a more accurate solution.
How to process training?
The process of training a machine learning model involves several steps, which can vary depending on the specific algorithm and data being used. However, a general overview of the process is as follows:
Data preprocessing: The first step in training a machine learning model is to preprocess the data. This can involve tasks such as cleaning the data, transforming it into a usable format, and splitting it into training and testing sets.
Model selection: The next step is to select a machine learning algorithm that is suitable for the problem being addressed. This can involve evaluating the strengths and weaknesses of different algorithms, as well as considering factors such as model complexity, interpretability, and accuracy.
Model initialization: Once an algorithm has been selected, the model needs to be initialized with appropriate parameter values. This can involve randomly initializing the model parameters, or using a pre-trained model as a starting point.
Training: The training process involves updating the model parameters to minimize the difference between the predicted outputs and the true outputs for the training data. This is typically done using an optimization algorithm such as stochastic gradient descent, which adjusts the model parameters based on the gradient of the loss function.
Validation: During training, it is important to monitor the performance of the model on a validation set, which is a subset of the data that is not used for training. This can help to identify overfitting or underfitting, and allow for adjustments to the model.
Hyperparameter tuning: Machine learning models often have hyperparameters, which are settings that are not learned during training but are set before training begins. These can include learning rate, regularization strength, and the number of hidden layers in a neural network. Tuning these hyperparameters can improve the performance of the model on the validation set.
Testing: Once training is complete, the final model is evaluated on a separate testing set to estimate its generalization performance on new, unseen data.
Deployment: The final step is to deploy the trained model in a production environment, where it can be used to make predictions on new data. This can involve integrating the model into a software system or deploying it as a web service.
Tools for federated learning
There are several tools and frameworks available for implementing federated learning, some of which are:
TensorFlow Federated: TensorFlow Federated (TFF) is an open-source framework developed by Google that enables developers to implement federated learning using TensorFlow, a popular machine learning library. TFF provides a set of APIs for building and training federated learning models.
PySyft: PySyft is an open-source framework developed by OpenMined that enables developers to implement privacy-preserving machine learning, including federated learning. PySyft provides a set of APIs for building and training federated learning models in Python.
Flower: Flower is an open-source federated learning framework developed by Adap, which enables developers to build and train federated learning models using PyTorch. Flower provides a set of APIs for building and training federated learning models, as well as tools for managing federated learning workflows.
FedML: FedML is an open-source framework developed by Tencent that provides a set of APIs for building and training federated learning models. FedML supports multiple machine learning frameworks, including TensorFlow, PyTorch, and Keras.
IBM Federated Learning: IBM Federated Learning is a commercial product developed by IBM that provides a platform for building and training federated learning models. The platform supports multiple machine learning frameworks, including TensorFlow, PyTorch, and Keras.
NVIDIA Clara Federated Learning: NVIDIA Clara Federated Learning is a commercial product developed by NVIDIA that provides a platform for building and training federated learning models. The platform supports multiple machine learning frameworks, including TensorFlow, PyTorch, and Keras.
The choice of federated learning tools and frameworks will depend on factors such as the specific use case, the machine learning frameworks used, and the technical expertise of the development team.
Conclusion
Through this article, we were able to see that federated learning opened the way to promising new possibilities in terms of privacy-friendly machine learning. By preserving sensitive data where it is collected, this decentralized approach enables collaboration without compromising security. We explained how federated learning generally works, with training local models and aggregating updates to form a powerful global model. Libraries like TensorFlow Federated are starting to democratize these techniques among developers. Although still at the research stage, the first use cases in personal assistants, health or finance suggest the potential of federated learning. Its challenges, such as data heterogeneity or bandwidth, remain to be resolved for large-scale deployment. With the exponential growth of personal data collected, this technique heralds profound changes in the world of AI. By combining the advantages of collaborative learning with absolute respect for privacy, federated learning could become essential. Its future progress will ensure the responsible development of artificial intelligence.