From Loops to Lightning - How Transformers Outran RNNs
Transformers: The Evolution Beyond RNNs
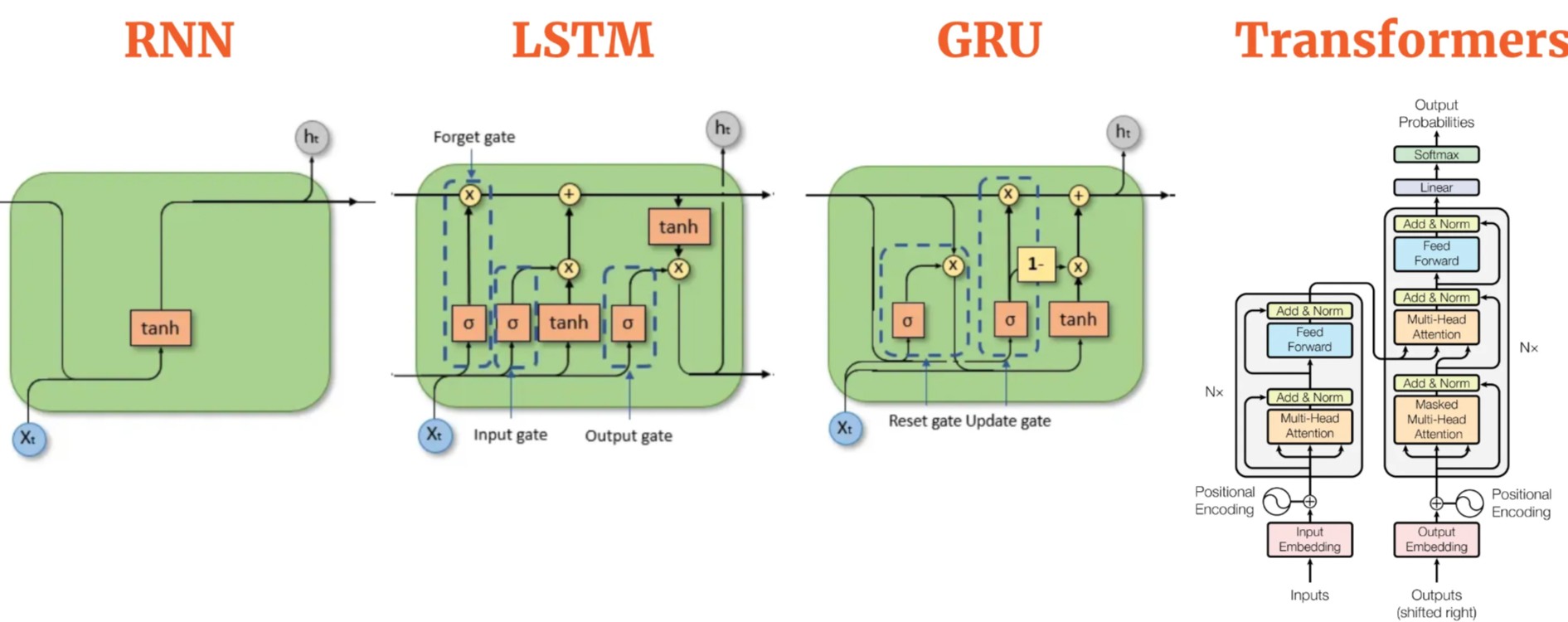
Before the advent of Transformers, Recurrent Neural Networks (RNNs) were the go-to models for handling sequential data, where the order of elements plays a crucial role — as is the case in natural language processing, time series, and other domains. Inspired by traditional feedforward neural networks, RNNs introduced the ability to process data step by step, maintaining a form of memory across the sequence.
However, this sequential approach comes with significant limitations. First, RNNs process inputs one element at a time, preventing full utilization of modern GPUs, which are designed for parallel computation — this makes training relatively slow. Second, RNNs struggle to capture long-range dependencies within sequences. As information is passed from step to step, it tends to degrade or vanish, especially over long distances, leading to what is commonly known as the vanishing gradient problem.
It is in this context that Transformers revolutionized the field. While inspired by the encoder-decoder frameworks of RNNs, Transformers remove the notion of recurrence entirely, replacing it with a fully Attention-based mechanism. This allows the model to focus directly on the most relevant parts of a sequence, regardless of their position.
With this innovation, Transformers not only surpassed RNNs in performance on key NLP tasks — such as machine translation, text summarization, and speech recognition — but also unlocked new applications across various domains, including computer vision and bioinformatics.
So why did Transformers replace RNNs? Because they directly address the two critical limitations of recurrent models:
- They enable parallel processing of sequence data, significantly speeding up training.
- They effectively capture long-range dependencies through the Attention mechanism.
In short, the rise of Transformers represents a natural and necessary evolution beyond the structural limitations of RNNs. Next, let’s dive deeper into how this groundbreaking architecture works.
The Transformer Architecture
Overview
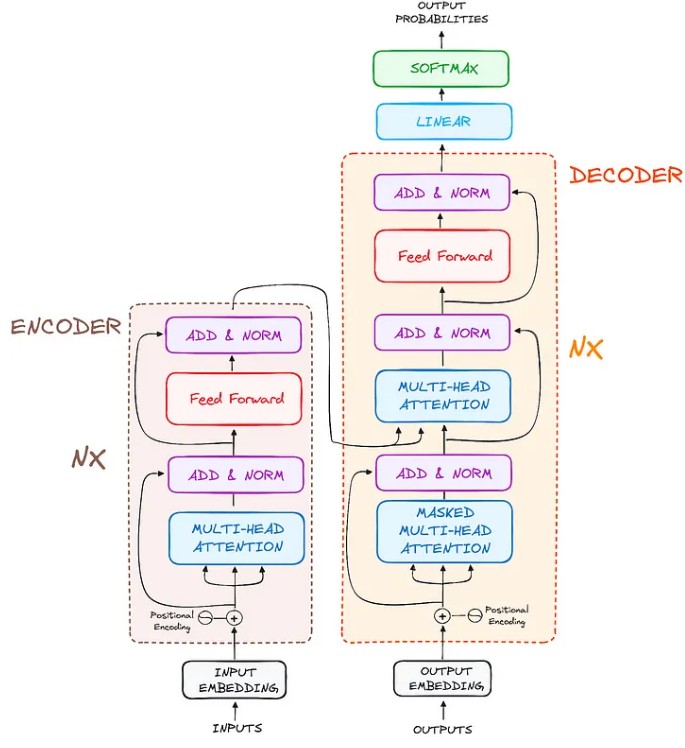
Originally designed for tasks like machine translation, Transformers are highly effective at converting input sequences into output sequences. They are the first model to rely entirely on the self-attention mechanism, without using RNNs or convolutional networks. However, they still maintain the classic encoder-decoder structure.
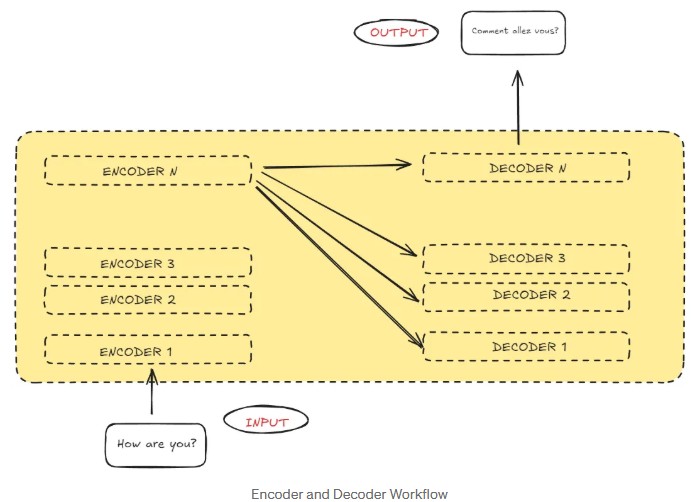
If we think of the Transformer as a black box for translation, it takes a sentence in one language — say, English — and translates it into another language, like Spanish.
Now, if we take a closer look at this black box, it consists of two main parts:
- The encoder takes the input (for example, “How are you?”) and transforms it into a matrix representation.
- The decoder uses this encoded information to gradually generate the translated sentence, such as “Comment allez vous?“.
In reality, both the encoder and decoder are made up of multiple stacked layers, all with the same structure. Each encoder layer processes the input and passes it to the next one. On the decoder side, each layer takes input from both the last encoder layer and the previous decoder layer.
In the original Transformer model, there were 6 layers for the encoder and 6 layers for the decoder, but this number (N) can be adjusted as needed.
Now that we have a general idea of the Transformer architecture, let’s dive deeper into how the encoders and decoders work.
Encoder Workflow
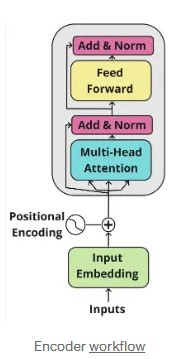
Transformers are currently the basis for many advances in natural language processing (NLP). They have enabled models such as BERT, GPT, and T5 to achieve impressive results. At the heart of these models is the Transformer encoder, which transforms input data (such as sentences) into machine-readable information.
In this section, we will simply explain the key elements that make up this encoder: embeddings (which transform words into numbers), positional coding (which indicates word order), self-attention (which allows the model to know which words are important), normalization and residual connections (which help stabilize learning), and finally the feed-forward layer (which processes the information before moving on to the next step).
Each of these elements is essential for the Transformer to perform so well on tasks such as translation, summarization, and text comprehension.
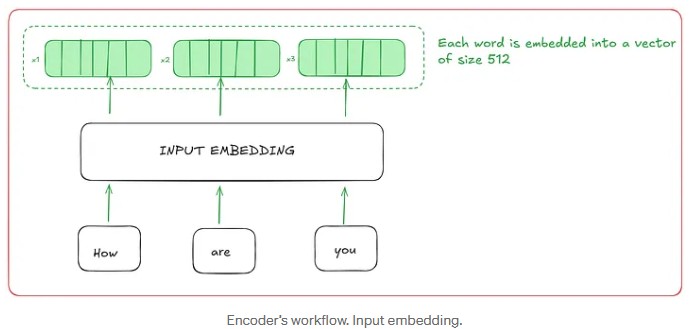
1. Input Embeddings
In a Transformer, the very first step is to convert words into numbers. Computers don’t directly understand words or sentences like we do; they need numbers to work. This is where input embedding (or “vectorizing words”) comes in. This step is only done in the very first encoder (often called the “bottom encoder”).
How it works:
- We take the sentence as input: for example, “How are you?”
- This sentence is split into tokens (i.e., words or pieces of words). Example: “How”, “are”, “you”.
- Each token is transformed into a vector, e.g., [0.25, -0.14, 0.67, …], via an embedding layer.
- These vectors are not random; they capture word meaning. For example, “king” will be closer to “queen” than to “apple” in this mathematical space.
- The size of each vector is always the same: in basic Transformers, each vector has 512 dimensions (that is, 512 numbers inside, regardless of the word).
2. Positional Encoding
Transformers, the artificial intelligence models revolutionizing language processing, have a unique characteristic: unlike their predecessors like recurrent neural networks (RNNs), they don’t process the words of a sentence one by one. Instead, they analyze all the words simultaneously, which allows them to be much faster.
However, this approach poses a problem: how can the model understand the order of the words? After all, the meaning of a sentence crucially depends on the order in which the words are placed. For example, “The cat sleeps on the mat” has a very different meaning from “The mat sleeps on the cat!” Without information about the order, the Transformer could confuse these two sentences.
An Ingenious Trick
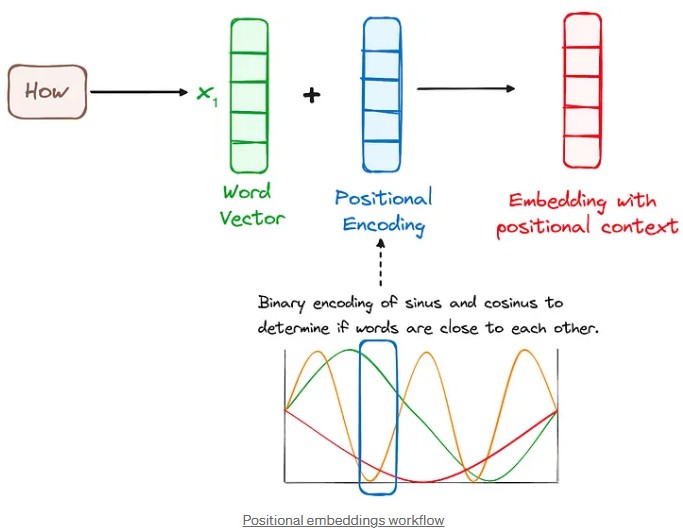
To solve this problem, researchers invented a technique called “positional encoding.” The idea is simple: we add information to each word that indicates its position in the sentence. It’s a bit like giving each word an address.
How it Works: Mathematical Waves to Encode Position
Instead of using simple numbers to encode the position, we use mathematical waves, specifically sine and cosine functions. Each position in the sentence receives a unique “mathematical signature” created from these waves.
Why use sines and cosines? These functions have interesting properties:
- They are periodic: They repeat, which is convenient for long sentences.
- They are different: We use waves of different frequencies (faster or slower) to encode each position. Thus, each position has a unique signature.
In Practice: The Magic Addition
Word Representation (Embeddings): Each word in the sentence is first transformed into a vector of numbers called an “embedding.” This vector represents the meaning of the word.
Encoding the Position: For each position in the sentence, we calculate a vector of numbers using sine and cosine functions. This vector represents the position of the word.
Combining the Two: We add the word’s embedding vector and the position vector
Thanks to this addition, each word now has a representation that combines:
- Its meaning: The word’s embedding.
- Its position: The position vector encoded with sine and cosine waves.
3. Stack of Encoder Layers
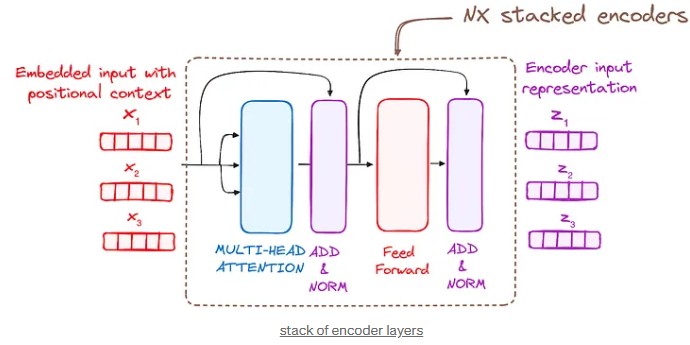
Each encoder layer contains:
a) Multi-Head Self-Attention: When a machine wants to understand or translate a sentence, the encoder is the main tool that reads and analyzes the sentence. It’s a bit like the model’s brain, trying to grasp the overall meaning before taking action.
The encoder uses a key method: self-attention. Imagine that each word in the sentence looks around and asks itself:“What other words help me better understand the meaning of the sentence?”
For example, in the sentence “You’re nice,” the word “es” will quickly understand that it is linked to “Tu,” because together they form the meaning of the action. This ability to make connections is crucial for properly grasping the context.
To make these connections, each word is transformed into three elements:
- Query: each word poses a question to other words, such as: “Who can help me understand?”
- Key: this is the identity of each word, a sort of badge that says: “This is who I am.”
- Value: this is the information the word carries and can share if needed.
👉 When a word poses its question (Query) and another word has the correct key (Key), then the answer is positive: we keep the Value of the found word to enrich the overall understanding.
And that’s not all! The encoder doesn’t just look at a single sentence. They repeat this process several times in parallel, slightly changing the way they ask questions or read the keys.
It’s as if several people were looking at the same sentence but from different perspectives: some will focus on the grammar, others on the tone or the cause-and-effect relationships.
b) Normalization and Residual Connections: 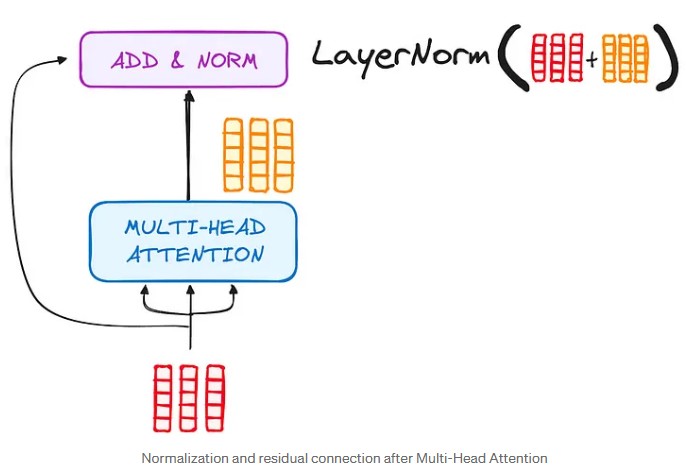
Once the encoder has completed the self-attention phase (where the words have looked at the other words to capture the context), we don’t move directly to the next step. Before that, two important operations are performed:
— The residual connection (or “shortcut”) Imagine that the result of the self-attention is like an enriched version of what the model has understood about the relationships between words. This result is added to the original input, meaning the representations of the words before self-attention.
👉 Why? Because it helps preserve the initial information intact and adds on top of what self-attention has discovered. It’s a bit like having a draft with ideas and highlighting the important parts without ever erasing your original text.
This is called a residual connection: we add the “residue” (the original input) to the layer’s result.
— Normalization Next, this sum passes through a normalization (called Layer Normalization). This step serves to stabilize the values to prevent them from becoming too large or too small.
👉 Why? It helps the model to learn better during training and avoids certain problems like forgetting or losing information (the famous “vanishing gradient” problem).
⚠️ This duo (residual + normalization) is a ritual in the encoder of Transformers: after every sub-layer (whether self-attention or feed-forward neural network), it is repeated.
c) Feed-Forward Neural Network: 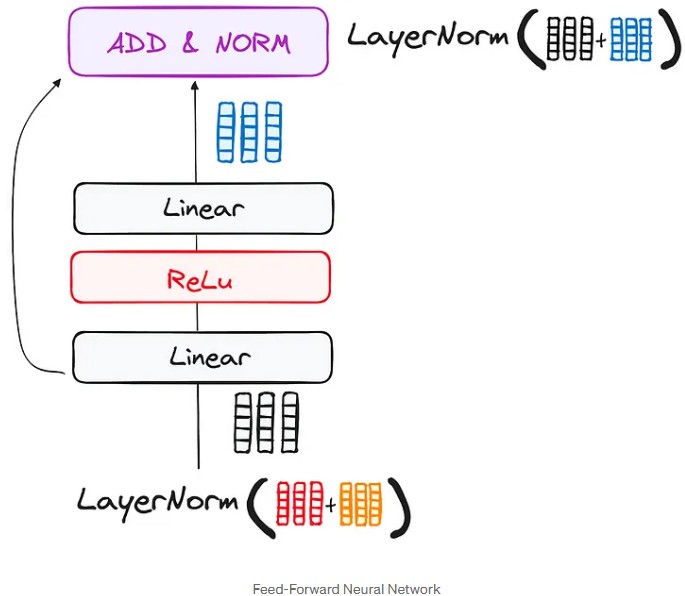
After the information passes through self-attention and the residual connection, it enters a new phase called the feed-forward neural network. Here’s how it works:
Information Transformation: The information first goes through a series of two simple transformations, called linear layers. These layers modify the information, kind of like changing its shape.
ReLU Activation: Next, there’s a small “filter” called ReLU. This filter helps make the information clearer and more useful for the next steps. It’s like highlighting important details to make them stand out.
Return to the Input: The transformed information is added back to the original information (this is the residual connection). This helps keep the original idea intact while adding new insights, without losing any important elements.
Normalization: Finally, everything goes through a last step called normalization. This step adjusts the information to ensure everything is balanced before moving on to the next phase.
4. Output of the encoder
The output of the final layer of the encoder is a set of vectors. Each of these vectors represents the input sequence, but with a rich and deep contextual understanding. These vectors contain all the information processed by the encoder, capturing the relationships and meaning of the words in the sequence.
This encoded output is then passed to the decoder in the Transformer model. The decoder uses these vectors to generate predictions or output sequences, such as translating text or producing a response. The encoder’s job is to prepare this information so that the decoder can focus on the correct parts of the input when decoding.
Think of the encoder’s function as building a tower made of layers. You can stack multiple encoder layers, and each layer adds more understanding by looking at the input from a slightly different perspective. Each layer uses its own attention mechanism, allowing it to learn different aspects of the input. As you stack layers, you increase the depth and richness of understanding. This process helps improve the transformer’s ability to predict and generate outputs more accurately, refining understanding layer by layer.
Decoder Workflow
Decoder Workflow
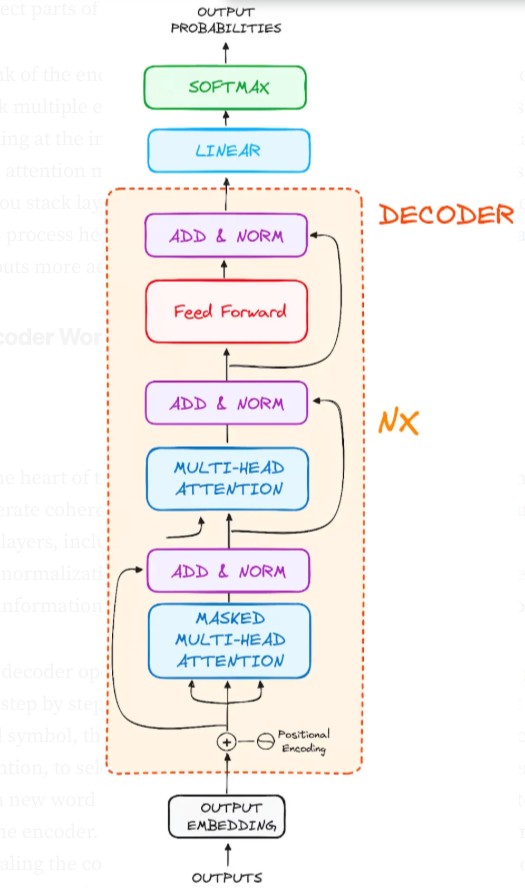
At the heart of the Transformer model lies the decoder, whose mission is to generate coherent text sequences. Like the encoder, it is made up of several sub-layers, including multi-head attention mechanisms, neural networks, and normalization techniques. These components work together to decode the information prepared by the encoder and produce intelligible text.
The decoder operates in an autoregressive manner, meaning it generates text step by step, based on the words it has already produced. It starts with a seed symbol, then uses the information from the encoder, enriched by attention, to select the next word. This process continues sequentially, with each new word influenced by the previous ones and by the context provided by the encoder. The decoder stops when it generates an end symbol, signaling the completion of the text sequence. In short, the decoder is an orchestrator that transforms encoded information into fluid and relevant text.
1. Output
Unlike the encoder, which receives the input sentence directly, the decoder requires a starting point to initiate text generation. This starting point is the famous “Outputs,” which feeds the “Output Embedding” at the very beginning of the decoding process. This first “Outputs” comes from the Special “Start of Sequence” (SOS) Token, a special token added to the model’s vocabulary. This token is not part of the common words of the language, such as nouns, verbs, or adjectives. Its main role is to signal to the decoder that a new text sequence will be generated, thus acting as a start signal. This SOS Token is therefore the very first “Outputs” sent to the “Output Embedding” layer to start the generation process.
2. Output Embeddings
The “Output Embedding” is a matrix, or a lookup table, that associates each token in the vocabulary, including the SOS token, with a numerical vector. This vector makes it possible to represent each token in a multidimensional space, where tokens with similar meanings are positioned close to each other. Concretely, when the SOS token is sent to the Output Embedding, the matrix extracts the vector corresponding to this token. This vector then becomes the initial input to the decoder. It is this vector that will be combined with the positional encoding and processed by the different layers of the decoder, such as masked attention, multi-head attention, etc., to progressively generate the text sequence.
3. Positional Encoding
Positional encoding is a crucial step in the sequence processing process in a Transformer model, whether in the encoder or the decoder. This step comes after token embedding, and its role is to add information about the position of words in the sequence.
Transformer models do not process sequences sequentially, like RNNs or LSTMs, which process each word one by one in a specific order. Instead, the words are processed in parallel. However, this poses a problem: without an indication of their position, the model would not know whether the word “cat” comes before or after “eat.” This is where positional embeddings come in.
Positional embeddings add a unique vector to each word in the sequence to indicate its specific position. For example, the first word in the sequence could have a different positional encoding than the second word, and so on. These vectors are added to the word embeddings, allowing the model to maintain an understanding of word order.
It works like this: each token in the input sequence is associated with a vector representing its position, and then this positional encoding is added to the vector of the corresponding word. This allows the model to “know” the order in which the words appear in the sentence, and therefore better understand the context.
This process is identical in both the encoder and the decoder.
4. Stack of Decoder Layers
🔔 Important context before we begin:
We want to train a model for translate englsh sentence to french. During training, the complete French sentence is already available (because it’s part of the data the model needs to learn). But to prevent the decoder from “cheating” by looking at future words during training, we use a mask in the self-attention process. This mask is like a filter that prevents the model from seeing subsequent words in the sentence while it learns to make predictions.
a) Masked Self-Attention: 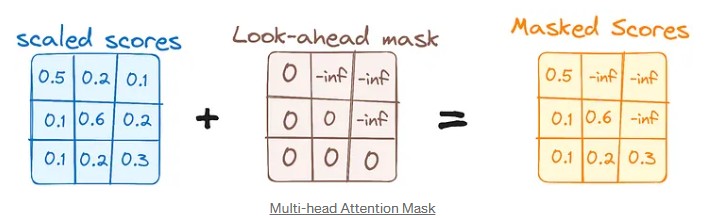
🔍 Role during training:
When the decoder learns to generate the French sentence, it must only use the words already generated (on the left) and not see future words (on the right).
➡️ Concrete example: Let’s imagine we’re learning to generate: “The cat was sitting on the carpet”
When the model has to learn to predict the word “sitting”, it can only use:
“The” “cat” “was” And cannot see subsequent words like “on” or “the carpet” even if they are available in the example.
🛑 Why? Because in real life, when generating text, we never have future words in advance.
💡 How does it work technically?
We apply a triangular mask (called a causal mask) to the attention matrix. This mask places “-∞” on the attention scores of future words. Result: the decoder learns to look only at words already known to predict the next one. 🎨 Simple analogy: It’s like writing a sentence without cheating: when you write the word “assis,” you only look at what you just wrote before, not what comes after.
b) Encoder-Decoder Multi-Head Attention or Cross Attention 🔄 What’s changing here:
Once the masked self-attention is complete, the decoder will look for clues in the encoded English sentence.
➡️ Concrete example: Still for the word “assis” to be generated, the decoder will consult the encoded English sentence “The cat sat on the mat”.
It will ask itself:
“Where is the key information in the English?”
Here, it will notice that the word “sat” is important because it is the verb to be translated as “assis”. 🧠 Where does this information come from?
The encoder’s outputs, which are available for ALL English words from the start (because the English sentence is encoded in its entirety before starting the decoder).
⚠️ But be careful:
The decoder still looks ONLY at the words already generated on the French side, thanks to the masked self-attention seen just above. But for these words, he can use ALL English words via the encoder to better understand them.
🎨 Simple analogy: It’s as if you were translating sentence by sentence:
You write “assis” on the French side, and each time you look at the complete English sentence to check how to translate it correctly.
b) Feed-Forward Neural Network
⚙️ Last step of a decoder layer:
Here, each word processed by attention is then refined. The feed-forward network will transform the word representation by applying two linear layers and a non-linear activation.
➡️ Example: The internal representation of the word “assis” is improved to be ready to move on to the next step (e.g., predicting the next word “sur”).
🎨 Simple analogy: It’s as if, after choosing the word “assis,” you further refine your idea by adding details and nuances before writing the next word.
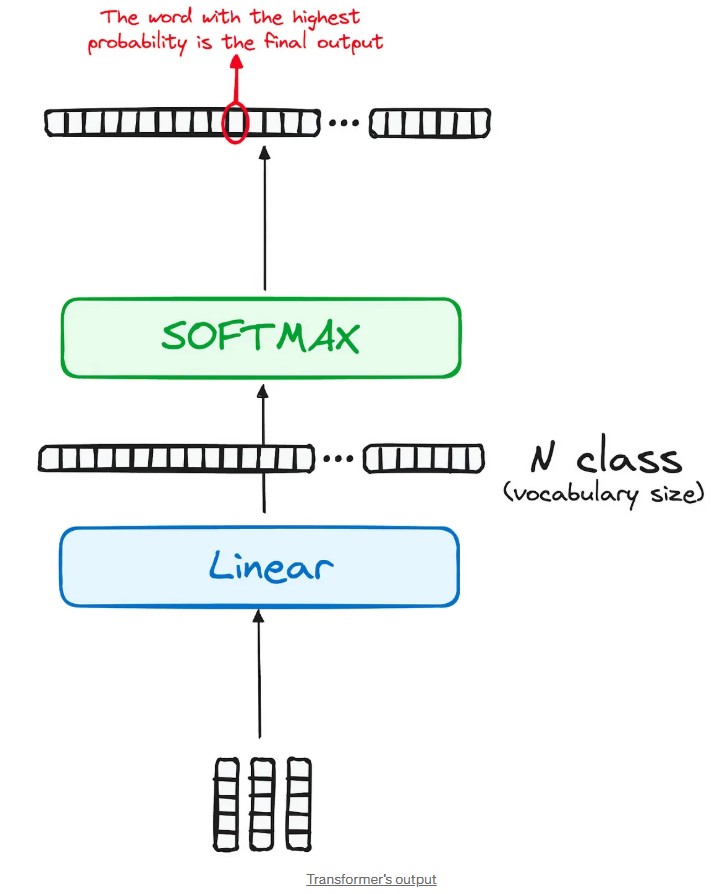
c) Linear Classifier and Softmax for Generating Output Probabilities
After passing through all the decoder layers (masked self-attention, encoder-decoder attention, feed-forward network), we obtain a vector representation for the word the model is about to generate. But at this stage, it’s still just an abstract vector, with no word assigned yet.
🎯 What happens next?
Linear Classifier: This vector is fed into a linear classifier (a linear layer). The classifier transforms the vector into a list of scores, one score for each word in the vocabulary. Example: If the model knows 10,000 words, it will produce 10,000 scores (one for “sat,” another for “jumped,” etc.).
Softmax: The softmax function takes these raw scores and turns them into probabilities. Each word gets a probability representing how likely it is to be the correct word in this context. Example: “sat” : 65% “jumped” : 20% “ran” : 10% The remaining words will have smaller probabilities.
Selecting the final word: The model picks the word with the highest probability (e.g., “sat” at 65%). This word becomes the newly generated word, and will be used as input for the next step to predict the following word. Simple analogy: It’s like playing a guessing game with multiple choices: You look at all the possible options (all 10,000 words), You think: “Hmm… 65% chance it’s ‘sat,’ 20% for ‘jumped’…” Then you choose the most likely answer.
Why Transformers Changed Everything ?
The Transformer architecture has fundamentally reshaped the landscape of natural language processing (NLP) and sequence modeling.
Unlike Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), which process sequences token by token in order, Transformers introduced parallel processing thanks to their attention mechanisms. This shift allowed models to capture long-range dependencies much more efficiently, without being limited by sequential bottlenecks.
🚀 Key breakthroughs of Transformers over RNNs:
Full attention span: Transformers can directly “attend” to every word in a sentence at once, while RNNs struggle with remembering distant words due to vanishing gradients.
Faster training: By processing all tokens in parallel during training (in the encoder), Transformers drastically reduce computation time compared to the step-by-step nature of RNNs.
Scalability: Transformers easily scale to large datasets and massive model sizes (e.g., GPT, BERT), unlocking unprecedented performance on tasks like translation, summarization, and text generation.
🧠 A smarter architecture:
By combining self-attention, masked attention, cross-attention, and feed-forward layers, the Transformer builds highly contextualized word representations, making it a universal tool not just for NLP, but also for vision, audio, and multi-modal tasks.
Today, almost every state-of-the-art model — from ChatGPT to BERT — relies on the Transformer backbone, making it one of the most influential breakthroughs in AI history.