The Rise of Smart Video Processing - From CNNs to Transformers
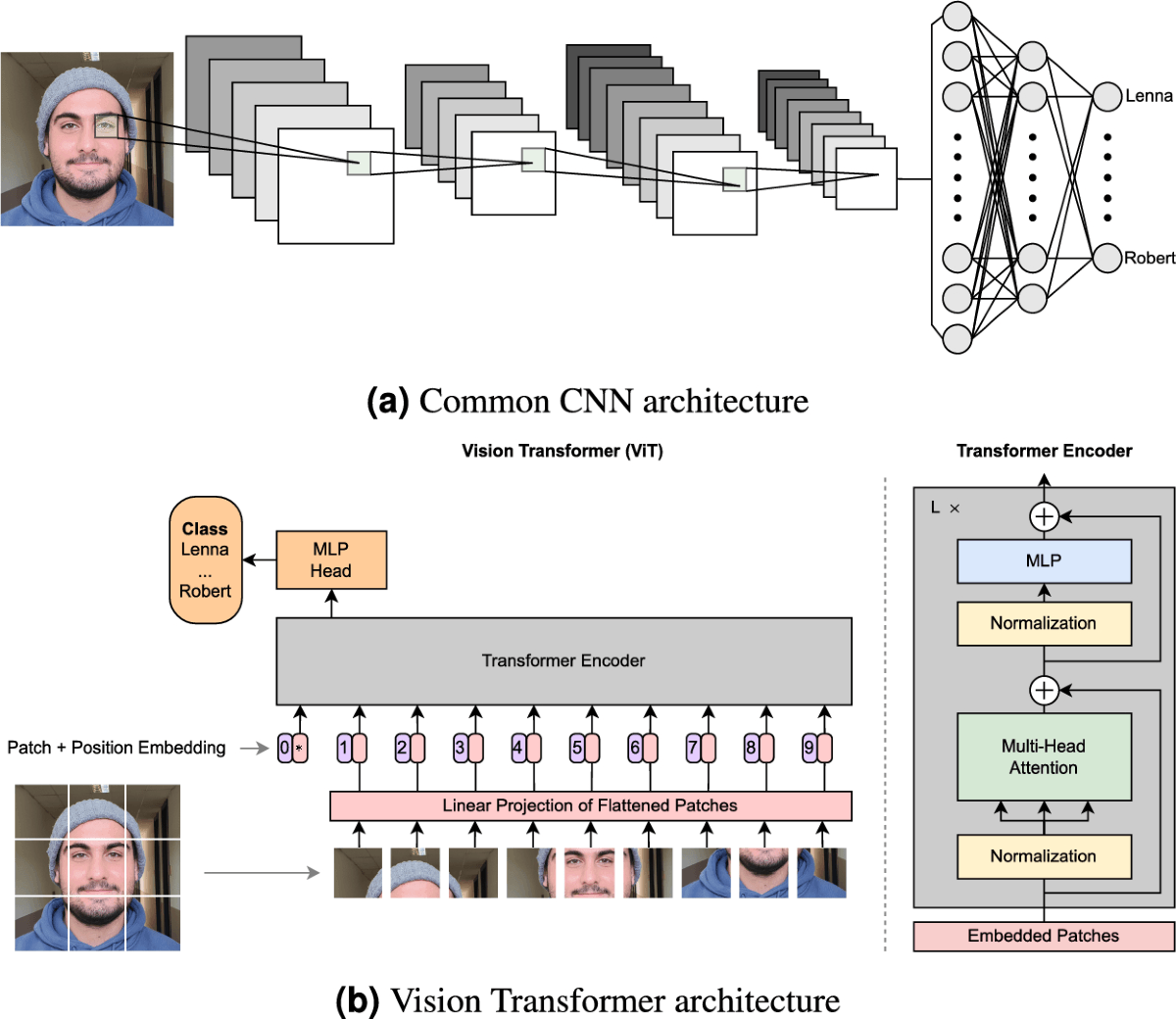
From CNNs to Transformers
Today, video has become an essential means of communication. According to Sandvine’s Global Internet Phenomena Report 2023, video content accounts for more than 65% of global Internet traffic, with an estimated annual growth of 24%. This spectacular evolution has led to the rise of numerous applications, ranging from online education to telemedicine, as well as digital advertising, virtual reality (VR), and many other fields.
Despite its growing importance, video processing and manipulation are still absent from many school curricula. That’s why this blog invites you to explore this fascinating universe, covering topics such as video understanding, captioning, localization, and much more.
Whether you are a curious beginner or a passionate learner seeking improvement, this blog will guide you through the essential techniques to better understand and master video.
📌 Ready to dive into the captivating world of video processing? Then let’s begin! 🚀
The Evolution of Video Understanding: From Frames to Intelligence
Understanding a video is much more than just watching a sequence of moving images. It’s a fascinating technical challenge where artificial intelligence plays a key role. Historically, the first approaches aimed to break down videos by analyzing each frame individually. These methods attempted to identify important visual elements, such as edges or shapes, to convert them into usable data.
But here’s the issue: these techniques had limitations. They required complex manual adjustments and struggled with unpredictable situations, such as fast movements, lighting changes, or hidden objects. Fortunately, the arrival of Deep Learning changed everything. These revolutionary algorithms have automated video analysis, making it faster, more accurate, and, above all, more adaptable.
The First Step: 2014–2016
This is where it all began. Researchers introduced the first neural networks for video analysis, laying the foundation for everything that followed. While these early models had limitations, they paved the way for major breakthroughs.
- Two-Stream CNNs: A simple yet powerful idea — one network processed images (to capture visual details), while another focused on motion (to analyze actions).
- 3D CNNs: A game-changer that enabled the simultaneous analysis of both spatial and temporal dimensions.
- CNN-LSTMs: By combining Convolutional Neural Networks (CNNs) with Long Short-Term Memory (LSTM) networks, these models brought a deeper understanding of sequences, making video analysis far more intelligent.
These pioneering approaches were promising but still lacked the speed and accuracy required for real-world applications.
The Era of Improvements: 2017–2019
In the following years, video analysis took a huge leap forward. The focus was no longer just on identifying objects or actions in individual frames — it became about merging spatial and temporal information to interpret videos in a more holistic way.
🔹ActionVLAD introduced a groundbreaking approach to combine spatial and temporal data, ensuring more coherent and meaningful video analysis.
🔹 R(2+1)D built on previous methods by breaking down 3D convolutions into separate spatial and temporal steps, improving action recognition.
🔹 TSM (Temporal Shift Module) and SlowFast Networks revolutionized video analysis:
- TSM enabled faster processing without sacrificing accuracy.
- SlowFast captured both fast-moving details and long-term context, significantly enhancing performance.
At the same time, the introduction of large-scale datasets like Kinetics-400 provided the perfect training environment. These datasets contained diverse and realistic videos, allowing models to generalize better to real-world scenarios.
💡 In short, video AI wasn’t just getting smarter — it was becoming faster, more adaptable, and more powerful than ever before!
The Rise of Transformers: 2020 and Beyond We have now entered an era where AI-powered video understanding has reached unprecedented levels. Thanks to cutting-edge architectures, models can analyze videos more accurately, efficiently, and intelligently than ever before.
🔹 Video Transformers (TimeSformer): Traditional CNN-based approaches had limitations in capturing long-range dependencies across frames. TimeSformer introduced self-attention mechanisms, allowing models to analyze global relationships throughout a video rather than just local patterns. This resulted in higher precision and better contextual understanding.
🔹 Hierarchical Models (MViT & VideoSwin):
- MViT (Multiscale Vision Transformer) refined video analysis by progressively learning representations at different scales, making it more adaptable to complex scenes.
- VideoSwin extended the Swin Transformer concept to videos, using shifted windows for efficient yet powerful video processing.
🔹 Lightweight Models (X3D): While accuracy is essential, real-world applications also demand speed and efficiency. X3D (Expandable 3D CNN) optimized both accuracy and computational cost, making high-quality video analysis accessible on a large scale.
Why Are These Advances Crucial?
The evolution of video analysis technologies represents much more than just technical progress. It reflects a deep transformation in how machines interact with the visual world. Moving from traditional, manual, and limited methods to intelligent algorithms capable of interpreting videos with unprecedented accuracy and speed has opened the door to revolutionary applications.
These advances are crucial in many fields:
- Security and surveillance: Identifying suspicious behaviors in real time
- Autonomous driving: Understanding the road environment to prevent accidents
- Media and entertainment: Offering more relevant recommendations and immersive experiences
- Healthcare: Analyzing medical videos to detect anomalies with precision
Each step of this evolution has helped solve major technical challenges while making these tools more accessible and versatile. These technologies no longer just “see”; they understand, interpret, and react. This is a breakthrough that redefines the standards of what artificial intelligence can achieve, paving the way for future innovations.
What’s Next: Exploring Techniques and Technologies
In our next article, we will dive deeper into the various techniques and technologies that make video analysis possible. We will explore modern approaches, from convolutional neural networks (CNNs) to the latest video transformers.
We will also detail fundamental concepts such as spatiotemporal analysis, self-attention mechanisms, and lightweight architectures, illustrating their role in real-world applications.
Stay with us to discover how these technological solutions are transforming not only how videos are understood but also the industries in which they are used!