Deep Learning basics for video — Convolutional Neural Networks (CNNs) — Part 1
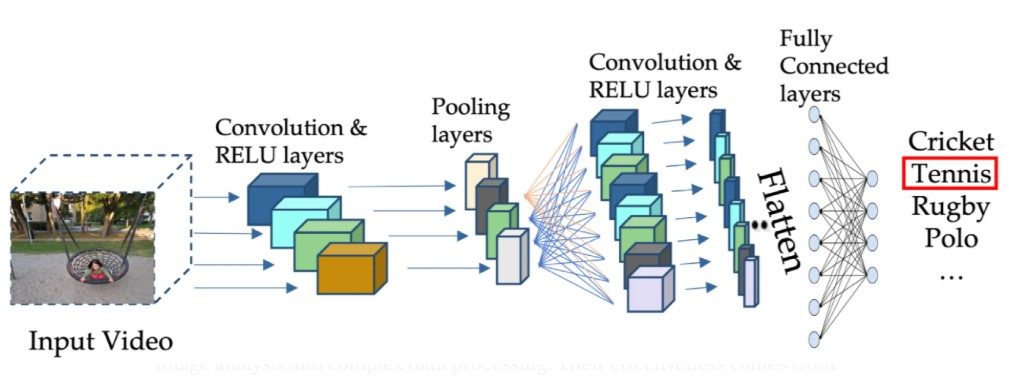
Convolutional Neural Networks (CNNs)
With the rise of deep learning, Convolutional Neural Networks (CNNs) have become a key technology, transforming image and video processing. These specialized neural networks are designed to replicate the functioning of the human visual cortex, allowing machines to analyze images by automatically extracting relevant visual features.
Since their introduction in 1989 for handwritten digit recognition, CNNs have evolved significantly, becoming essential in various fields that require image analysis and complex data processing. Their effectiveness comes from their ability to detect visual patterns with remarkable accuracy, often outperforming traditional computer vision techniques.
Today, CNNs play a vital role in multiple applications, including:
- Computer vision, such as image classification, facial recognition, object detection, and segmentation.
- Natural Language Processing (NLP), where convolutions are applied to matrix representations of words for text analysis.
- Recommendation systems, by interpreting user preferences based on images and videos.
In this section, we will examine the structure of CNNs and their fundamental components.
Structure and Components of CNNs
A Convolutional Neural Network (CNN) is a specialized neural architecture designed to efficiently process visual data. Its operation relies on a series of layers that extract, transform, and interpret the features of an image to deduce a classification or prediction.
Thanks to this hierarchical architecture, a CNN can capture simple patterns (edges, textures) in the early layers and more complex structures (shapes, objects) in the deeper layers.
A CNN consists of several types of layers, each playing a specific role in image analysis:
- Convolution — The core operation of the CNN, it applies filters to extract visual features (edges, patterns, textures).
- Activation — After convolution, an activation function, such as ReLU (Rectified Linear Unit), is applied to introduce non-linearity, enabling the network to learn complex relationships.
- Pooling — A dimensionality reduction technique that preserves essential information while reducing the complexity of the model.
- ** ** — These layers transform the extracted features into final decisions, such as image classification.
Convolution: Extraction of visual Characteristics
An image can be represented as a matrix of pixels, where each pixel contains a light intensity (for a grayscale image) or several values (Red, Green, Blue — RGB) for a color image.
But how can a machine identify shapes, textures or objects from this raw data? This is where convolution comes in! It is a mathematical operation that allows to extract characteristic patterns from an image and reveal its essential structures. This operation apply filters to an image to detect specific patterns, such as:
- 🖼️ Edges
- 🎨 Textures
- 🔳 Shapes and geometric structures
Each filter acts like a lens, highlighting certain aspects of the image, making it easier for machines to automatically recognize visual elements.
🔍 A Simple Analogy: The Magnifying Glass
Imagine looking at an image through a magnifying glass. As you move it across different parts of the image, you can observe specific details more clearly, such as the edges of an object or a unique texture. Convolution does the same thing with a filter, but in a mathematical and systematic way.
Steps of convolution
1️⃣ Choosing the Filter (Convolution Kernel)
A filter is a small matrix of numbers (often 3×3 or 5×5) that interacts with an image to highlight specific features. Different types of filters serve distinct purposes:
- Edge detection filters (Sobel, Prewitt, Laplacian): Highlight sudden changes in brightness, making the edges of objects more visible

Blurring filter (Gaussian Blur): Applies a weighted average to smooth an image and reduce noise.

Sharpening filter: Enhances edges and improves image sharpness
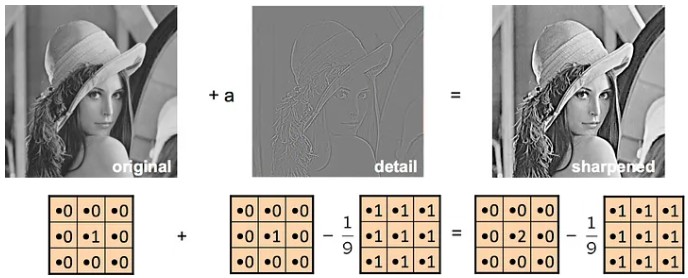
2️⃣ Applying the Filter to the Image (Convolution Operation) 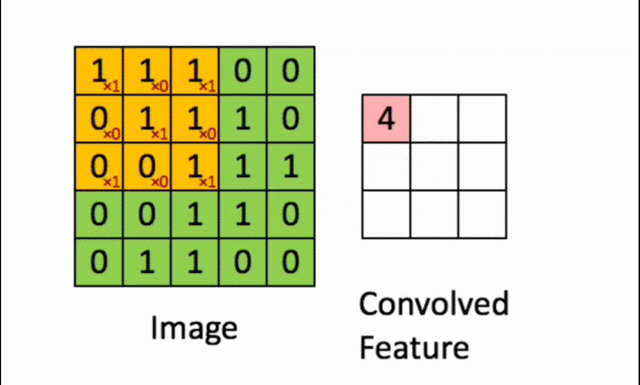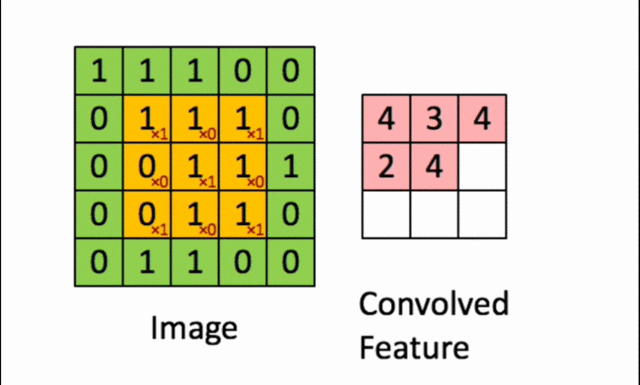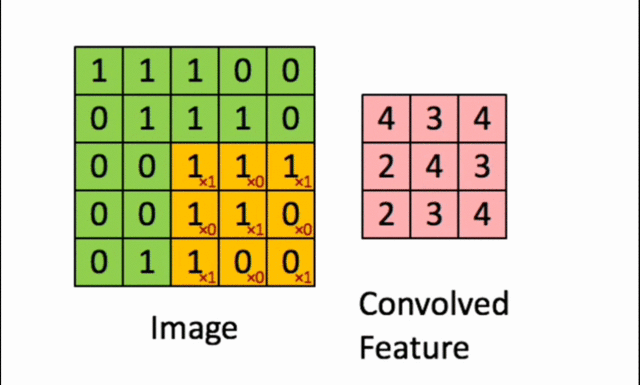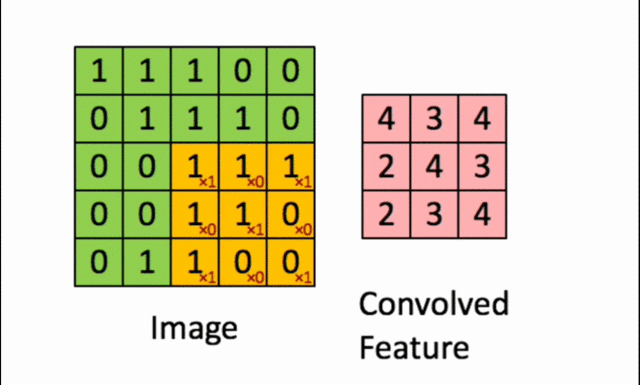
- The filter is applied to a specific region of the image.
- A pointwise multiplication is performed between the filter values and the corresponding pixel values.
- The sum of these results becomes the new pixel in the transformed image.
- The filter is then shifted to a new region, and the operation is repeated until the entire image has been processed.
Each resulting value depends on the applied filter. An edge detection filter will highlight the edges, while a blurring filter will smooth out fine details. The image obtained after convolution is called the Feature Map. It highlights essential information while eliminating irrelevant details.
Mathematical formula for the convolution
The convolution on an image I with a filter K is expressed as:
- S(i,j): Value of the resulting pixel after convolution at position (i,j).
- I(i+m,j+n): Value of the original image pixel, shifted by (m,n).
- K(m,n): Value of the kernel (filter) applied to the image region.
- k: Half the size of the filter; if the filter is of size N x N, then k = (N-1)/2
- Σ: Summation operation covering the entire area affected by the filter.
Activation Layers
After the convolution stage, where filters are applied to extract specific features from the image, the network generates a feature map. This map highlights relevant elements while eliminating unnecessary details. However, convolution alone has limitations. It can detect simple features, like edges, textures, or patterns, but it cannot model complex relationships or understand non-linearities in the data.
To address this limitation, an activation function is applied to each value in the feature map. This function introduces non-linearity into the model, which is essential for enabling the network to learn complex relationships and perform tasks like classification or object detection.
Why use activation layers after convolution?
Convolution is a powerful operation for feature extraction, but it is inherently linear. A linear operation satisfies two properties:
- Proportionality: If the input is multiplied by a constant, the output is also multiplied by the same constant.
- Additivity: The sum of two inputs corresponds to the sum of the two outputs.
While convolution can detect simple relationships, such as brightness differences between pixels, it cannot handle complex or non-linear relationships, which are necessary for tasks like recognizing objects in varying conditions.
Limitations of linearity in convolution
Consider the example of recognizing a cat in an image. Convolution alone can detect basic features, such as edges (like the cat’s ears) or repetitive patterns (such as fur texture). However, these features are insufficient for recognizing a cat, especially in more challenging scenarios like:
- A cat with a bent ear
- A partially hidden cat
- A cat seen from an unusual angle
In these cases, convolution struggles to combine simple features and understand complex relationships, such as “these contours form a cat’s face.” This is where activation functions come in.
Role of activation functions
Activation functions introduce non-linearity into the network, enabling it to model complex relationships. This is critical for tasks that involve more than simple linear transformations, such as recognizing objects that change in size, orientation, brightness, or position.
In a convolutional network, each layer progressively learns to detect more abstract features:
- The first layers identify simple patterns (e.g., edges, textures).
- Intermediate layers combine these patterns to detect shapes (e.g., ears, eyes).
- Deeper layers integrate these shapes to recognize objects (e.g., a cat’s face).
Without non-linearity, this hierarchy of abstraction would not be possible, as each layer would merely perform a linear combination of data from the previous layer.
Now, let’s talk about differents types of activation functions in part 2?👉